Matrix Multiplication and Broadcasting - The Heartbeat of Data Transformations
Understanding the transformation of input through weights and biases is fundamental in machine learning. Let's dive into how matrix multiplication plays a crucial role. It's all about matrix multiplication, the bread and butter of transforming inputs into meaningful outputs. Let's dive into how weights, biases, and inputs dance together in this mathematical ballet.
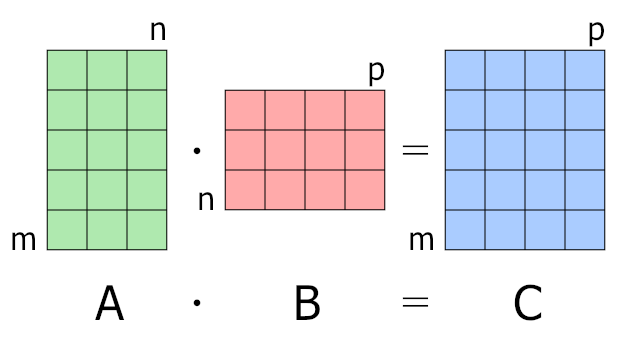
For matrix multiplication, the number of columns in the first matrix must be equal to the number of rows in the second matrix. The result matrix has the number of rows of the first and the number of columns of the second matrix.
Exploring Matrix Multiplication in Detail
Matrix multiplication is not just about numbers; it's about understanding how data flows through layers of computation in machine learning models.
Setting Up Our Matrices:
- Input Matrix \(\mathbf{X}\): This represents our data, with each row being a sample and each column a feature. For 100 samples and 3 features, we have:
- Weights Vector \(\mathbf{W}\): Our weights are like the tuning knobs for our model; they adjust how much each feature influences the outcome:
- Bias \(b\): A little nudge to shift our predictions, just a single number:
The Process
- Linear Combination \(Z\): The first step in our logistic regression model is to compute \(z\), the linear combination of our features with their respective weights plus the bias:
- Predicted Probabilities \(\hat{y}\): We then pass our linear combinations through the sigmoid function to squash the results between 0 and 1, turning them into probabilities:
But why do we end up with 100 results? Let's examine this more closely!
The Dot Product - Vector Multiplication
This simple operation is the heartbeat of matrix multiplication, allowing our model to compute how much each feature contributes to the prediction. The dot product is the sum of the element-wise products of two vectors.
Matrix Multiplication
Matrix multiplication is not just about numbers; it's about understanding how data flows through layers of computation in machine learning models. Consider Matrix A with dimensions 2x2 and Matrix B also with dimensions 2x2:
Step-by-Step Matrix Multiplication
Here's the color-coded step-by-step representation of matrix multiplication. To compute \(\mathbf{C} = \mathbf{A} \cdot \mathbf{B}\):
Step #1:
- First Element of \( \mathbf{C} \):
Step #2:
- Second Element of the First Row:
Step #3:
- First Element of the Second Row:
Step #4:
- Second Element of the Second Row:
After completing these steps, the resulting matrix \( \mathbf{C} \) would be:
Each step highlights the corresponding elements from \(\mathbf{A}\) and \(\mathbf{B}\) used in the calculation, with the color blue indicating the active elements in the multiplication.
Dimensionality in Matrix Multiplication
Matrix multiplication is not only about the arithmetic of numbers but also about how dimensions play a crucial role in the operation. Here's a detailed look:
- Let's revisit Matrix A and Matrix B:
- The Requirement for Multiplication: The number of columns in \(\mathbf{A}\) must equal the number of rows in \(\mathbf{B}\). Both \(\mathbf{A}\) and \(\mathbf{B}\) are 2x2, fitting this requirement perfectly. But, if we take a column from \(\mathbf{B}\), say \( \begin{bmatrix} 2 \\ 3 \end{bmatrix} \), we can multiply \(\mathbf{A}\) by this vector!
Step #1 - Matrix A by Column of B:
- First Row Multiplication:
- Second Row Multiplication:
Resulting in:
This operation indeed matches the first column of the full matrix multiplication result! Now, take only the first row of \(\mathbf{A}\) and multiply it by \(\mathbf{B}\):
Step #1 - Row of A by Matrix B:
- First Column Multiplication:
- Second Column Multiplication:
Resulting in:
This matches the first row of our previous matrix multiplication result.
Generalizing Matrix Multiplication
- When we multiply a matrix \(\mathbf{A}\) of size \(M \times N\) by a matrix \(\mathbf{B}\) of size \(N \times P\), the result is a matrix \(\mathbf{C}\) of size \(M \times P\):
- Dimensionality Rules:
- The dimensions of \(\mathbf{A}\)'s columns must match the dimensions of \(\mathbf{B}\)'s rows (
N). - The resulting matrix \(\mathbf{C}\) has the row dimension of \(\mathbf{A}\) (
M) and the column dimension of \(\mathbf{B}\) (P).
This process helps in understanding how matrix multiplication transforms data across neural network layers or any other application requiring feature transformation. It's about ensuring that the 'middle' dimensions align, allowing for a fusion of input data with weights to produce an output that can be interpreted in the context of our model's needs.
Exploring Different Approaches to Matrix Multiplication
Matrix multiplication isn't limited to one technique; there are various ways to conceptualize and compute it. Here's how we can think about this operation both horizontally (column by column) and vertically (row by row):
Horizontal Stacking - Multiply A by Columns of B:
Let's split matrix \(\mathbf{B}\) into columns \(b_1\) and \(b_2\):
Then, we can multiply matrix \(\mathbf{A}\) by each of these vectors and stack the results horizontally:
- First Column of \(\mathbf{C}\):
- Second Column of \(\mathbf{C}\):
Thus, the resulting matrix \(\mathbf{C}\) is:
Vertical Stacking - Multiply Rows of A by B:
Now, let's split matrix \(\mathbf{A}\) into rows \(a_1\) and \(a_2\):
Then, we multiply each row of \(\mathbf{A}\) by \(\mathbf{B}\) and stack the results vertically:
- First Row of \(\mathbf{C}\):
- Second Row of \(\mathbf{C}\):
Thus, the resulting matrix \(\mathbf{C}\) is:
Both horizontal and vertical stacking methods yield the same result, highlighting the flexibility in matrix multiplication techniques while emphasizing the importance of understanding how dimensions interact.
Matrix Multiplication: An Interesting Dimensionality Example
In the world of matrix operations, sometimes the dimensionality rules allow for some intriguing transformations. Let's dive into an example where the dimensions seem unconventional:
- Matrix \(\mathbf{A}\): 3 rows and 1 column,
- Matrix \(\mathbf{B}\): 1 row and 2 columns.
Here, \(\mathbf{A}\) and \(\mathbf{B}\) have matching dimensions for multiplication, specifically the column dimentions of \(\mathbf{A}\) matches the row dimentions of \(\mathbf{B}\):
- Computing the Output:
The resulting matrix \(\mathbf{C}\) has dimensions \(3 \times 2\), showing how the multiplication can indeed change the shape of our data.
Matrix Multiplication: Column-Row Way
Let's use this method for Matrix \(\mathbf{A}\) and Matrix \(\mathbf{B}\):
- First Column of \(\mathbf{A}\) by First Row of \(\mathbf{B}\):
- Second Column of \(\mathbf{A}\) by Second Row of \(\mathbf{B}\):
Now, we sum these resulting matrices:
This method, where we multiply a column from one matrix by a row from another, effectively constructs the result matrix \(\mathbf{C}\) by summing these intermediate results. Each element of \(\mathbf{C}\) is formed by considering the dot product between corresponding columns of \(\mathbf{A}\) and rows of \(\mathbf{B}\), which is a fundamental way to understand how matrix elements interact in matrix multiplication.
Broadcasting: Expanding the Dimensions
Now let's come back to our example. We know that our Matrix X is of 3 by 3 dimensions, and Matrix W is three rows with only one column. We then add a bias term B, which is just a scalar, equal to 1. The dimensionality of X * W results in a 3x1 matrix, and adding the scalar B involves an operation called broadcasting.
Broadcasting is a method used by most scientific computing libraries like PyTorch or NumPy to handle operations between arrays of different shapes. Here’s how it works:
- Broadcasting Rules:
- When performing an operation, compare the dimensions from right to left side.
- If the dimensions do not match, the shape with a size of 1 is stretched to match the other shape.
In our example, if we were to broadcast:
- Matrix
Awith shape(3, 1)(ourX * Wresult) - Matrix
Bwith shape(1, 4)(our biasBexpanded to matchX * Wfor broadcasting)
For the addition, we:
- Stretch
Ato matchBby duplicating the column four times. - Stretch
Bto matchAby duplicating the row three times.
Thus, both matrices would be aligned to have dimensions of 3x4, allowing for element-wise addition.
Broadcasting Example in Python
Let's see this in code using NumPy:
import numpy as np
# Define array A with shape (3, 1)
A = np.array([
[1],
[2],
[3],
])
print(f"Array A shape: {A.shape}")
# Define array B with shape (1, 4)
B = np.array([
[1, 2, 3, 4],
])
print(f"Array B shape: {B.shape}")
# Perform broadcasting addition
result = A + B
print("A + B result: ")
print(result)
print(f"Result of A + B shape: {result.shape}")
# Broadcasting the same for the matrix multiplication
matmul = A @ B
print(f"Matmul A @ B shape: {matmul.shape}")
print("Matmul result: ")
print(matmul)
Output:
Array A shape: (3, 1)
Array B shape: (1, 4)
A + B result:
[[2 3 4 5]
[3 4 5 6]
[4 5 6 7]]
Result of A + B shape: (3, 4)
Matmul A @ B shape: (3, 4)
Matmul result:
[[ 1 2 3 4]
[ 2 4 6 8]
[ 3 6 9 12]]
This code demonstrates:
- Broadcasting addition where
Ais extended across columns andBacross rows to perform element-wise addition, yielding a3x4result. - Matrix multiplication where
A(as a column vector) is multiplied withB(as a row vector), also yielding a3x4matrix.
Both operations use the broadcasting mechanism to align the arrays appropriately before performing the operation. The output shapes and values will confirm that the broadcasting worked as expected, providing insight into how matrix dimensions can be manipulated and aligned for operations in machine learning and data processing tasks.
Final Step: The Power of Broadcasting
Returning to our initial example, we have:
- Matrix
Xwith 100 samples and 3 features, leading to a 100x3 matrix. - Matrix
Wwith 3 weights, forming a 3x1 matrix after transposition. - Bias
Bas a scalar, which we can consider as having dimensions 1x1.
When performing the linear combination of X with W, we get a result with dimensions 100x1, as each sample in X is mapped to a single value through the weights. Now, we add B:
Broadcasting in Action
-
Applying Broadcasting Rules:
-
Step 1: The rightmost dimension of
B(1) matches with the leftmost dimension of the result ofX * W(1). This meansBcan be broadcasted along the rows of our result to match the 100 rows. -
Operation: We're adding a 1x1 matrix to a 100x1 matrix. Broadcasting stretches
Bto have the same number of rows as our result from the multiplication, effectively turning it into a 100x1 matrix where every element is1.
Thus, the addition operation looks like this:
The final output Z still has dimensions 100x1, giving us 100 linear combinations with the bias term added to each.
Takeaways
Remember, in machine learning, the shape of your data often dictates the shape of your solution!
-
Matrix Shapes: The shape of your matrices tells you a lot about the nature of your data and what operations are possible or necessary. Here, the shape of
Zafter broadcasting indicates that we now have a vector of 100 predictions, each adjusted by our bias term. -
Dimension Management: Understanding and managing dimensions is crucial in machine learning. Broadcasting allows us to perform operations that would otherwise require reshaping or looping over arrays manually, simplifying our code and making operations more efficient.
-
Predictive Power: With this setup, each element in
Zrepresents a 'score' for each sample, which, when passed through an activation function like sigmoid, gives us probabilistic predictions for classification tasks.