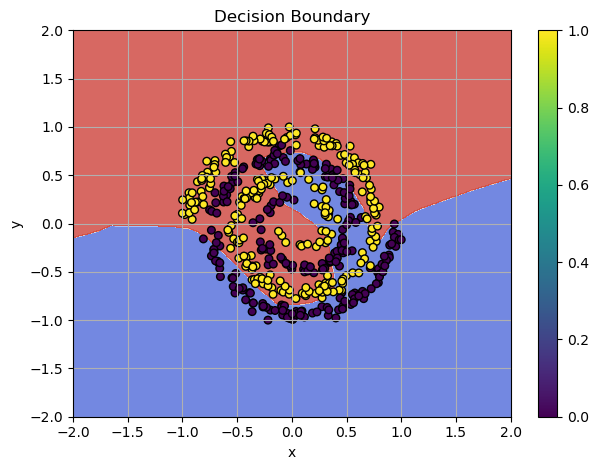
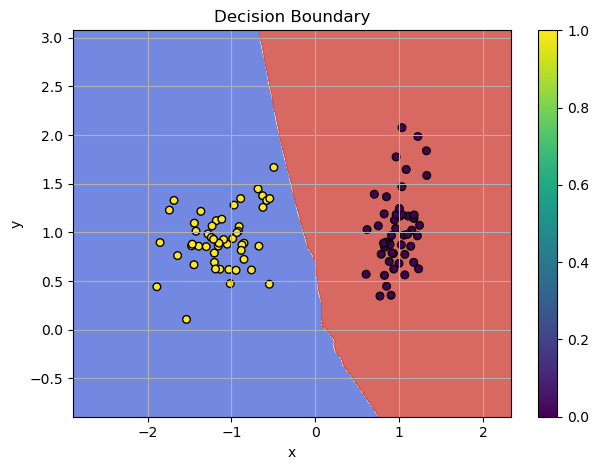
Classification in Depth – Cross-Entropy & Softmax
Fashion-MNIST is a dataset created by Zalando Research as a drop-in replacement for MNIST. It consists of 70,000 grayscale images (28×28 pixels) categorized into 10 different classes of clothing, such as shirts, sneakers, and coats. Your mission? Train a model to classify these fashion items correctly!
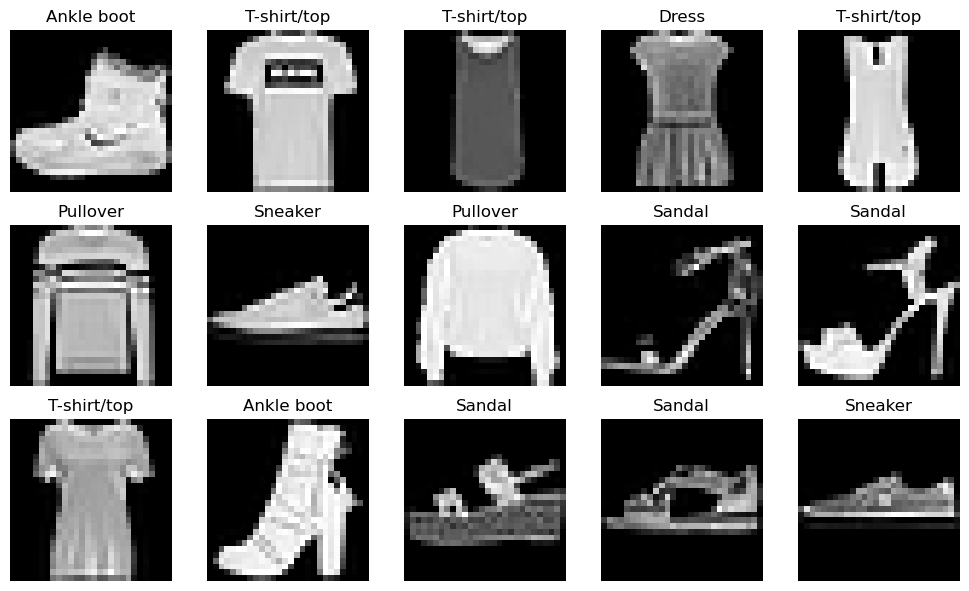
Fashion-MNIST Dataset Visualization