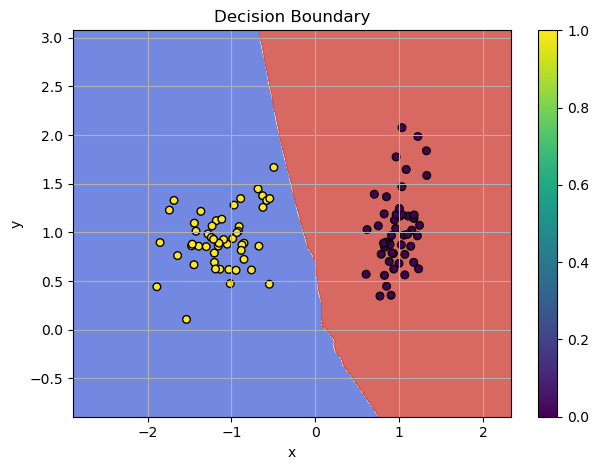
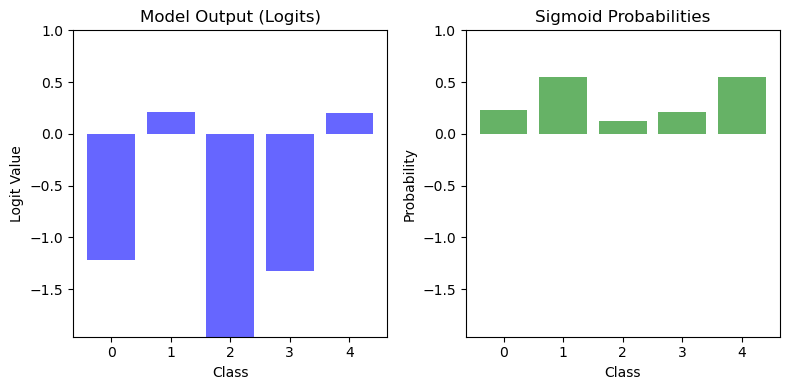
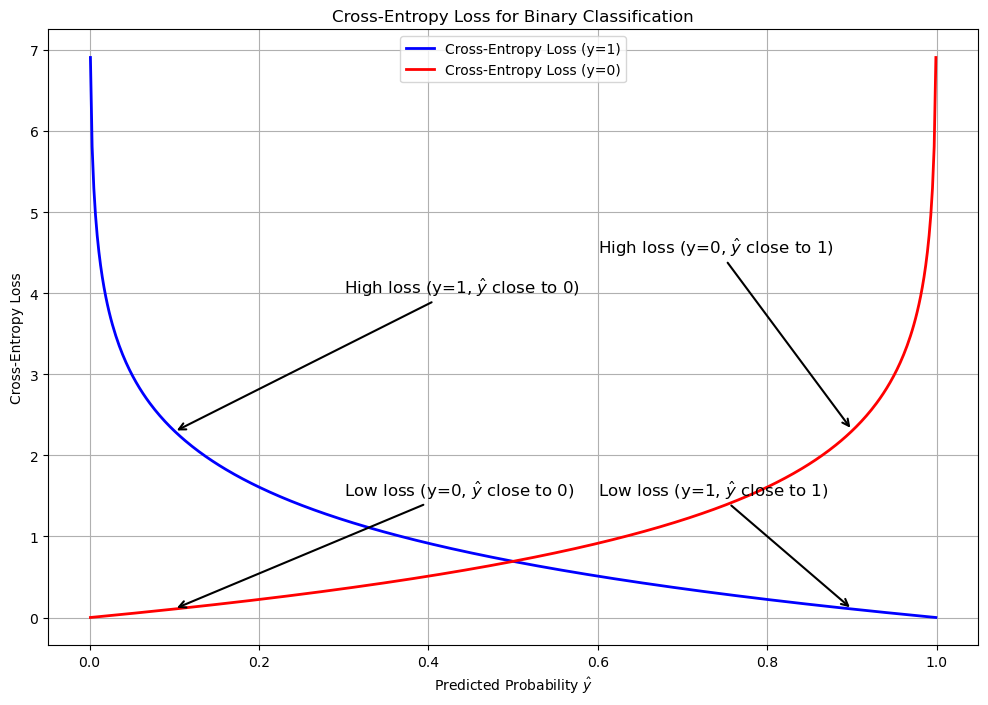
Solving Non-Linear Patterns with Deep Neural Network
The Perceptron, created by Frank Rosenblatt in the 1950s, was one of the first neural networks designed to classify patterns. Initially celebrated, it became a foundational milestone in machine learning.

Frank Rosenblatt and the Perceptron, a simple neural network machine designed to classify patterns