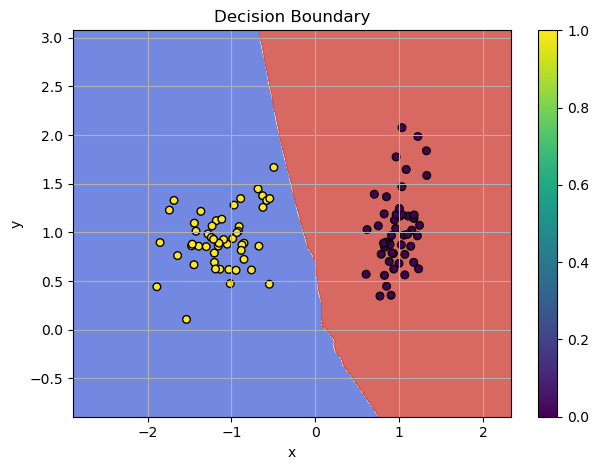
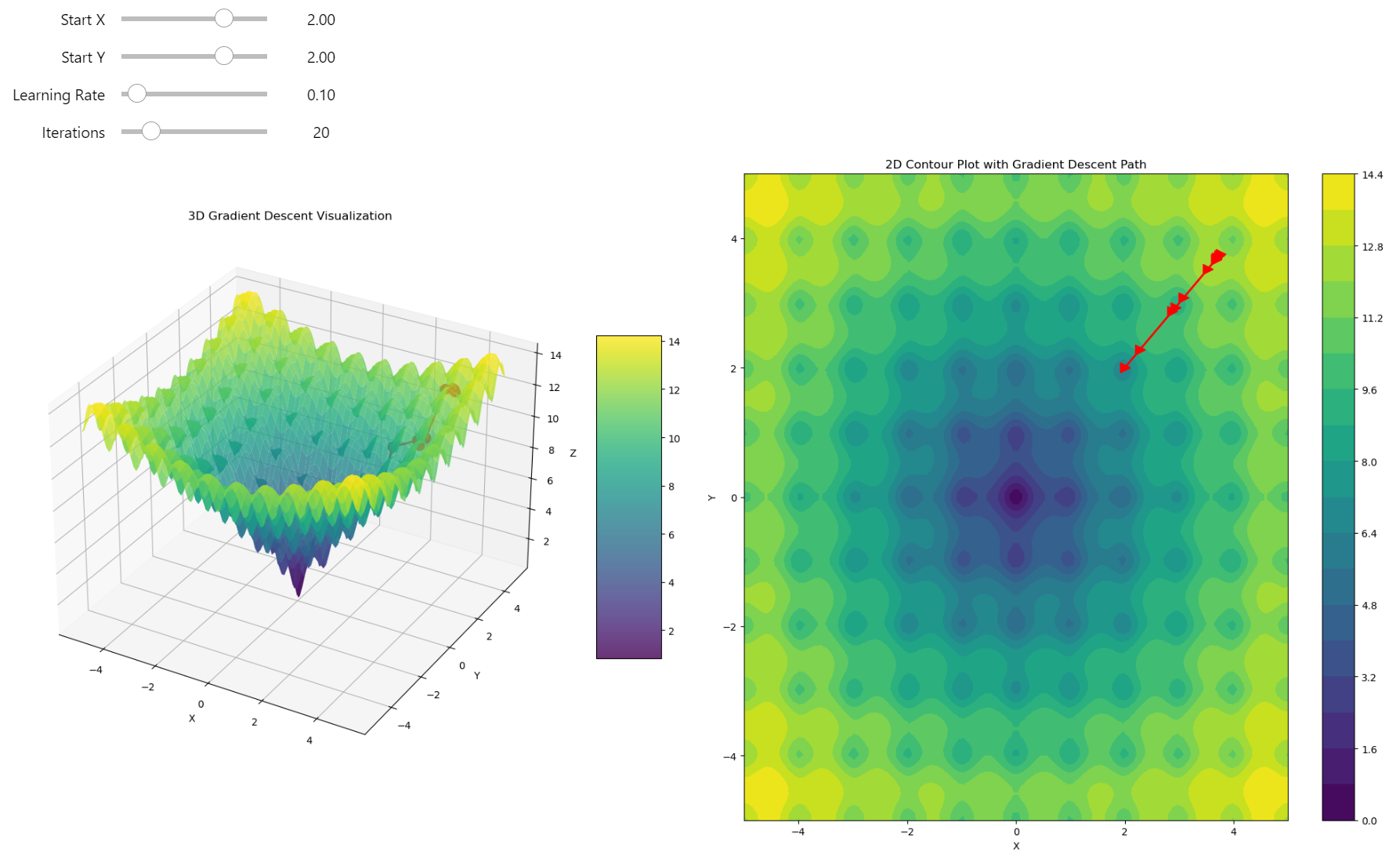
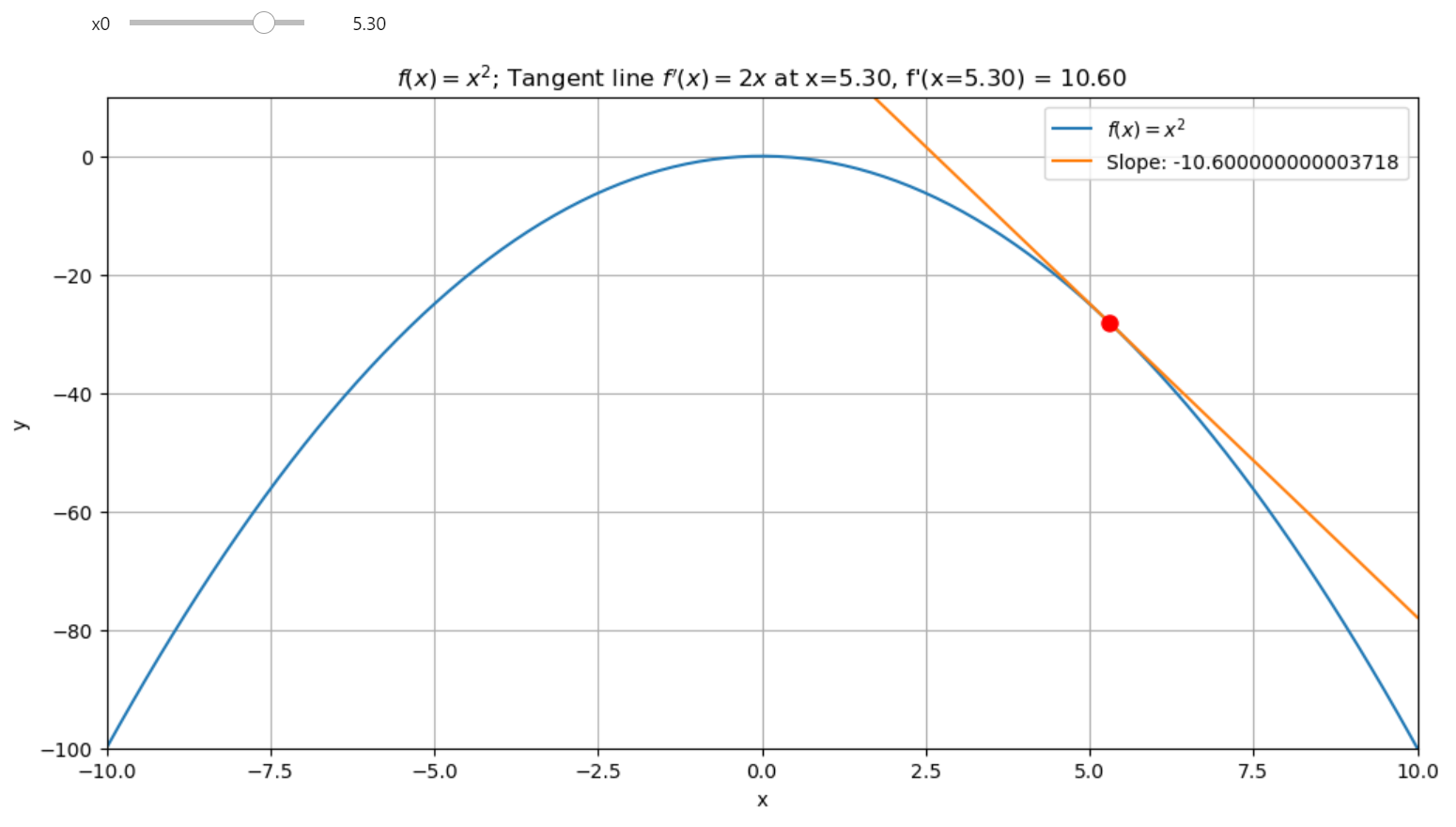
SGD, Momentum & Exploding Gradient
Gradient descent is fundamental method in training a deep learning network. It aims to minimize the loss function \(\mathcal{L}\) by updating model parameters in the direction that reduces the loss. By using only batch of the data we can compute the direction of the steepest descent. However, for large networks or more complicated challenges, this algorithm may not be successful! Let's find out why this happens and how we can fix this.
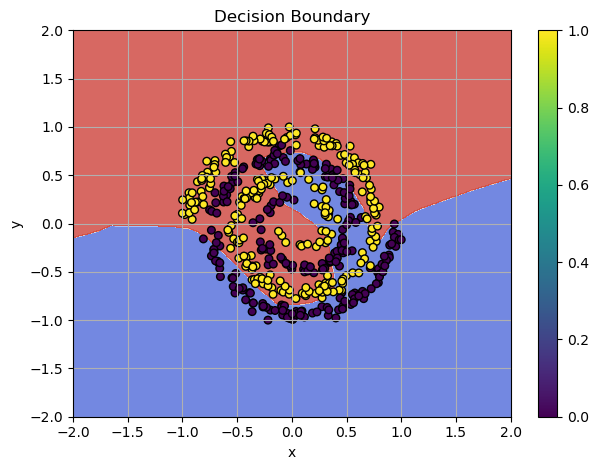
Training Failure: SGD can't classify the spiral pattern