Text-to-Speech (TTS) Models Overview, Little Theory and Math
Audio is a very complicated data structure, just take a look for a 1 sec waveform...
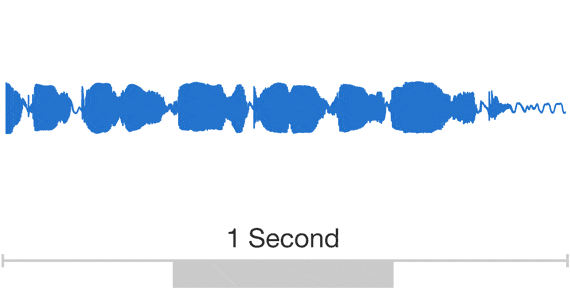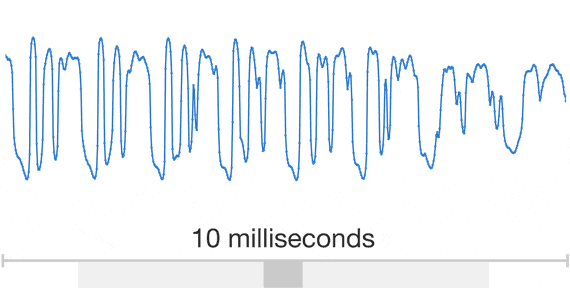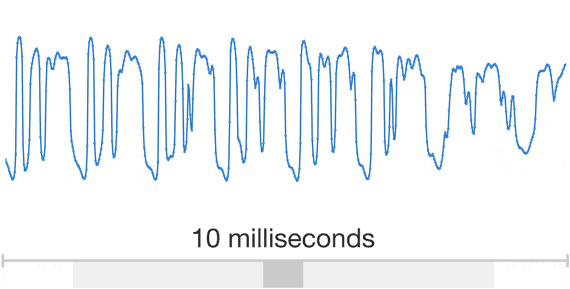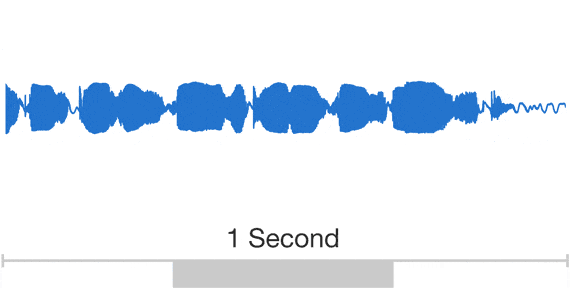 |
|---|
| Audio exhibits patterns at multiple time scales. Source: Google DeepMind. |
Developing a high-quality text-to-speech (TTS) system is a complex task that requires extensive training of machine learning models. While successful TTS models can revolutionize how we interact with technology, enabling natural-sounding speech synthesis for various applications, the path to achieving such models is often paved with challenges and setbacks.